Extracting data with Hpricot
For those (few) of you which haven't heard about it, Hpricot is a nice library for parsing HTML in ruby, created by the even nicer _whytheluckystiff, author of Poignant's Guide to Ruby, Camping and other ruby gems (may you excuse the pun? it was impossible to avoid it).
Since I saw one demonstration by Rob McKinnon at certain LRUG meeting, I have been willing to try Hpricot, but I hadn't seen an application for it yet. No more! I found myself today wanting to extract data from a table in a web page and suddenly I thought: this is a job for Hpricot!
. More specifically, I wanted to extract these EXIF tags, and I simply couldn't accept the mere thinking of entering that data manually. It needed to be automated!
Getting it
Getting Hpricot is very easy: ```bash sudo gem install hpricot
(if you're picky you can try more exotic ways of installing in its homepage). ```bash
gem install hpricot
if you're in windows, of course.
Understanding it is easy as well, specially if you have used jquery before. It's all about writing selectors for looking for things, so it helps a lot if the HTML document is well marked. Otherwise, you might have to end up doing lots of workarounds or extra code that could be avoided simply by having a class or id specified in the relevant elements.
Inspecting & traversing
So, once I got the library installed, I took a look at the page source code with Firebug. It is specially useful for this kind of jobs because it helps you to visualize the hierarchy of elements in the page, including classes and id's, so you don't have to traverse manually the HTML tree to gather the data you need.
What I was looking for was the table which contained the relevant data. In this case, we're lucky and even if the table hasn't got an id attribute which would make it uniquely identifiable in the whole document, it still has class="inner", which happens to be used only once in it, thus acting effectively as an element identifier.
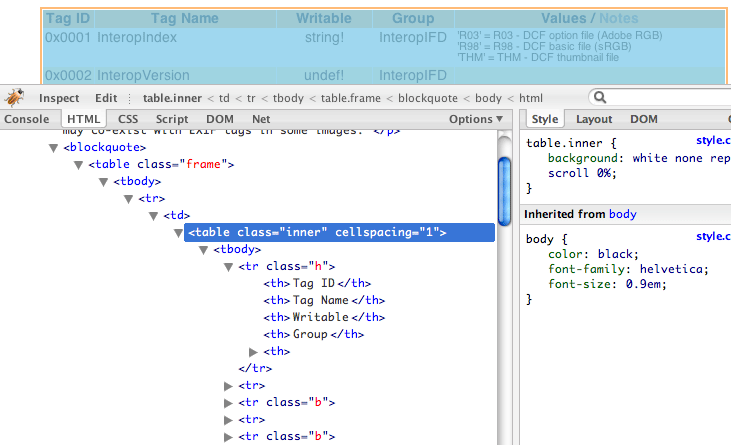
Note how Firebug is showing the tree path for the selected table. If we didn't have the class attribute, we would need to use a selector like "/html/body/blockquote/table/tbody/tr/td/table", but it will be something as simple as "/table.inner".
Hands on Ruby
Ok, so this is where we write a few lines of code which do a lot ;-)
First come the usual series of requires:
require 'rubygems'
require 'hpricot'
require 'open-uri'
Rubygems is required in order to load hpricot, and open-uri is required in order to directly read data from a URI. open-uri comes with ruby, so we don't need to install anything else.
Now we need to get the HTML file. It is as simple as
doc = Hpricot(open("http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/EXIF.html"))
but since I was doing lots of tests and didn't want to overload that guy's server, I simply saved the document as EXIF.html and loaded it with this instead:
doc = open("EXIF.html") { |f| Hpricot(f) }
At this point we have the HTML document in the doc variable, so what are we waiting for? We initialize a rows variable for holding the data that we'll extract:
rows = []
And now comes the real fun!
(doc/"table.inner//tr").each do |row|
cells = []
(row/"td").each do |cell|
if (cell/" span.s").length > 0
values = (cell/"span.s").inner_html.split('<br />').collect{ |str|
pair = str.strip.split('=').collect{|val| val.strip}
Hash[pair[0], pair[1]]
}
if(values.length==1)
cells < < cell.inner_text
else
cells << values
end
elsif
cells << cell.inner_text
end
end
rows << cells
end
Ok, not that fast. I'll elaborate a little more on the juicy bits.
(doc/"table.inner//tr").each do |row|
This is the key for reaching the main data. It's like saying I'm looking in doc for all the rows (the tr's) which are contained in a table whose class equals 'inner'
. When we use a / it means we want an immediate child. // means a child below the element. As I said before, it's all about selecting and traversing the tree.
With the last line of code, we get returned the content of each tr into the row variable. We can continue extracting data from within row, and that's exactly what we do with ```ruby (row/"td").each do |cell|
That one provides us with all the td elements immediately below the current row.
When we reach the td elements, all that is left is to extract the data for each cell and push it into the cells array, which will be pushed into the rows array. But we don't just copy the cell data as it is; some cells contain notes, and some of those notes contain lists of values. I think we can all agree that those lists of values are commonly called Hashes, and they undoubtedly deserve an special treatment!
```ruby
if (cell/" span.s").length > 0
So that's why I'm checking for the existance of an span with class == s inside each cell. If we find one, there's a note in this row, and probably there's one hash with values. I would say this is the funniest part of all:
values = (cell/"span.s").inner_html.split('<br />').collect{ |str|
pair = str.strip.split('=').collect{|val| val.strip}
Hash[pair[0], pair[1]]
}
I'm making use of the fact that each invoked function is returning another object, so that I can chain them consecutively instead of doing a series of assignments. And it reads like this: Take the html inside the span with class s, split it where you find a br, and for each of those split parts remove the surrounding whitespace and split it again where you find a =, so we get a pair of key-value values, remove the whitespace for those pairs as well and put them in a new Hash
.
At the end we finish with an array of rows and cells, where certain cells occasionally contain a Hash with the constants used by the row EXIF tag.
It's also interesting to note that the first row is unusable, because it corresponds to the th elements, so we'll simply do a ```ruby rows.shift
and it's gone. And to top it all, we could output the <strong>rows</strong> array to a yaml file, so that we do not need to run this each time we need the list of EXIF tags.
Arrays in ruby have a lovely method called <strong>to_yaml</strong> which dutifully generates a version of the array in yaml syntax. And it's very easy to output that to a file:
```ruby
File.open('hexif.yaml', 'w') { |f|
f << rows.to_yaml
}
And you're done! I hope you liked this small Hpricot tutorial/introduction... and if you have any suggestion or improvement please let me know!
Of course, you can get the complete source code here: hexif.rb. It is a ridiculous 61 lines, including some commented lines and white spaces. Come on get it and do something cool!